
Seaborn 개념
Seaborn은 python에서 제공하는 데이터 시각화를 위한 라이브러리이다. Matplotlib을 기반으로 만들어졌으며, 데이터 시각화를 보다 쉽고 가시적으로 진행할 수 있게끔해준다. seaborn 자체에 내장된 penguins dataset을 활용해 사용법에 익숙해져보자. 사용할 데이터 셋의 구성은 다음과 같다.
- species : 펭귄 종
- island : 서식지
- bill_length_mm : 부리 길이
- bill_depth_mm : 부리 위아래 두께
- flipper_length_mm : 팔 길이
- body_mass_g : 몸무게
- sex : 성별
import seaborn as sns
data = sns.load_dataset('penguins') # 데이터 로드
data = data.dropna() # 데이터 전처리Seaborn 기본 메서드
seaborn은 matplotlib을 기반으로 하기 때문에 대부분의 기능이 함께 사용된다.
- plt.title("제목"): 그래프의 제목을 설정
- plt.xlabel("x축 라벨"): x축의 라벨을 설정
- plt.ylabel("y축 라벨"): y축의 라벨을 설정
- plt.legend("범례명"): Seaborn에서는 hue 매개변수를 통해 그룹을 지정하면 자동으로 범례가 생성되며 Matplotlib과 동일하게도 사용가능하다.
Seaborn 사용 예제
Histplot
히스토그램은 연속형 데이터의 분포를 보여준다. 주로 데이터의 빈도수를 막대 형태로 시각화하여 데이터의 분포를 파악하는데 사용된다. 이때 막대의 높이는 해당 구간에 속하는 데이터의 개수를 나타낸다. KDE를 함께 표시하여 부드러운 추정 분포 곡선을 볼 수도 있다.
sns.histplot(data=data, x='flipper_length_mm', bins=15, kde=True)
plt.title('Histogram of Flipper Length (mm)')
plt.xlabel('Flipper Length (mm)')
plt.ylabel('Frequency')
plt.show()
Distplot
분포 플롯은 주로 데이터의 분포를 시각화하는 데 사용된다. 히스토그램과 함께 KDE 곡선을 함께 보여줌으로써 데이터의 분포를 보다부드럽게 확인할 수 있다.
sns.distplot(data['body_mass_g'], bins=15, kde=True)
plt.title('Distribution of Body Mass (g)')
plt.xlabel('Body Mass (g)')
plt.ylabel('Density')
plt.show()
Barplot
막대 그래프는 하나의 범주형 변수에 대한 다른 연속형 변수의 평균이나 기타 집계량을 시각화하는 데 사용된다.
sns.barplot(data=data, x='species', y='bill_length_mm', ci=None)
plt.title('Average Bill Length (mm) by Species')
plt.xlabel('Species')
plt.ylabel('Average Bill Length (mm)')
plt.show()
Countplot
카운트 플롯은 주어진 범주형 변수의 빈도수를 보여준다. 각 범주에 속하는 데이터의 개수를 막대로 표시하여 범주 간 비교를 할 수 있다.
sns.countplot(data=data, x='species', hue='island')
plt.title('Count of Penguins by Species and Island')
plt.xlabel('Species')
plt.ylabel('Count')
plt.legend(title='Island')
plt.show()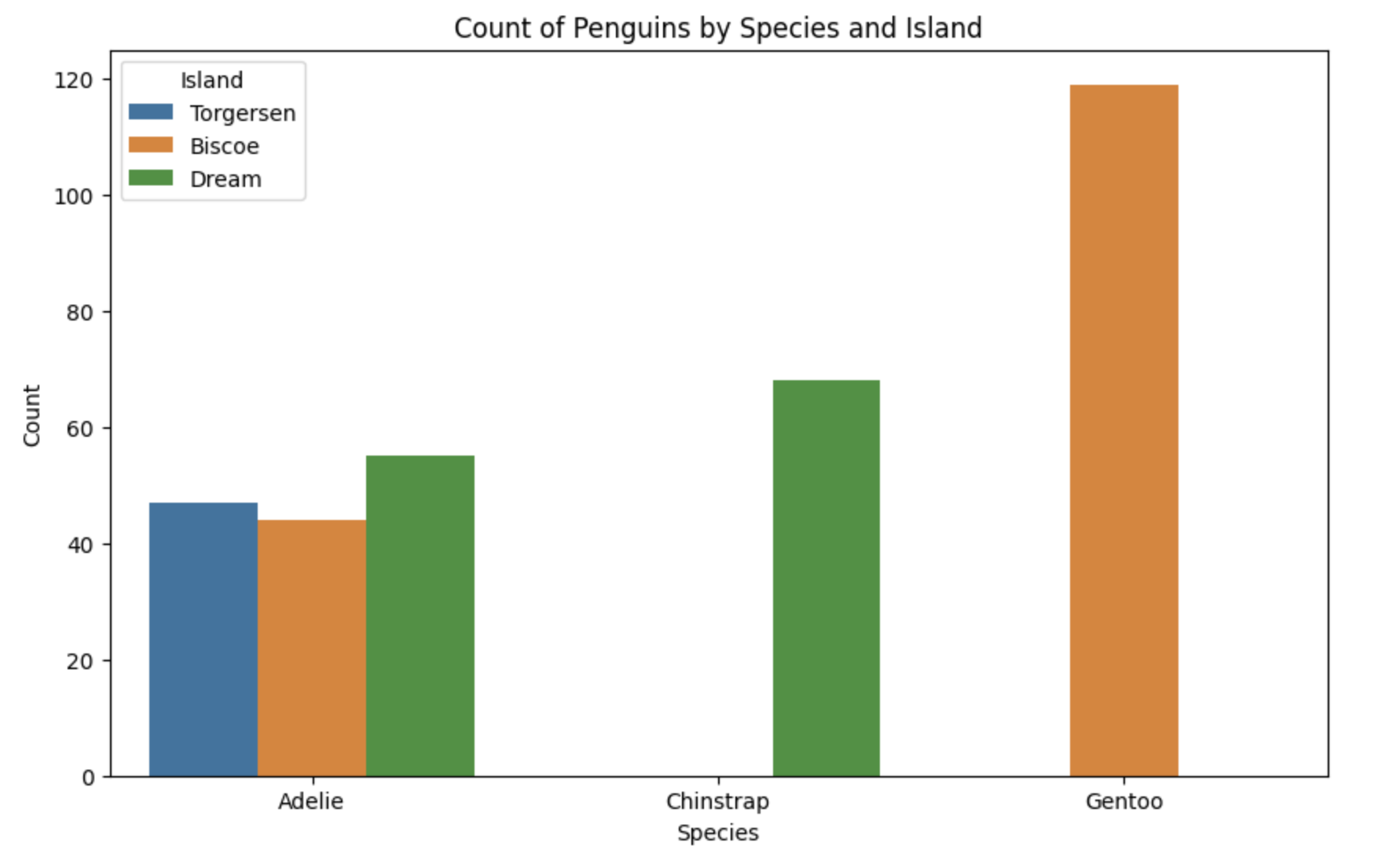
Boxplot
데이터의 분포를 시각화하는데 용이하다. 상자는 데이터의 사분위수 범위를 나타내며, 수염은 데이터의 전체 범위를 나타낸다. 이를 통해 데이터의 중앙값, 분포의 대칭성, 이상치 등을 시각적으로 확인 가능하다.
sns.boxplot(data=data, x='species', y='body_mass_g')
plt.title('Body Mass (g) Distribution by Species')
plt.xlabel('Species')
plt.ylabel('Body Mass (g)')
plt.show()
Scatterplot
산점도를 통해서는 두 연속형 변수 간의 관계를 시각화 할 수 있다. 각각의 그룹은 색상 또는 모양으로 구분 가능하다.
sns.scatterplot(data=data, x='flipper_length_mm', y='bill_length_mm', hue='species')
plt.title('Flipper Length vs Bill Length by Species')
plt.xlabel('Flipper Length (mm)')
plt.ylabel('Bill Length (mm)')
plt.legend(title='Species')
plt.show()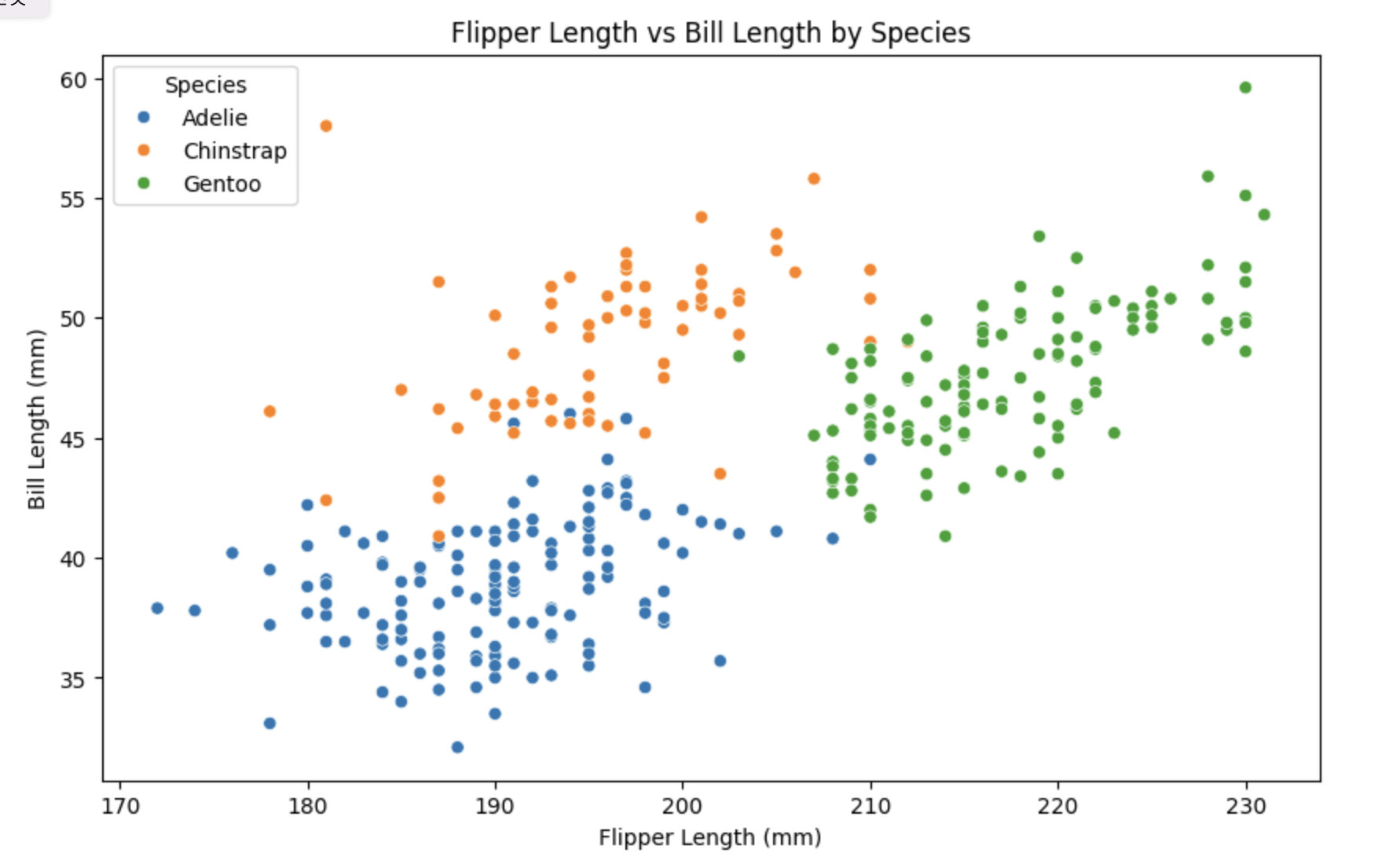
heatmap
히트맵은 두 개의 범주형 변수에 대한 평균값 또는 다른 집계를 색상으로 표시하여 데이터의 패턴을 시각화해준다. 주로 데이터의 밀도를 시각적으로 파악하거나 범주 간의 관계를 분석하는 데 사용된다.
heatmap_data = data.pivot_table(index='species', columns='sex', values='body_mass_g', aggfunc='mean')
sns.heatmap(heatmap_data, annot=True, cmap='YlGnBu')
plt.title('Average Body Mass (g) by Species and Sex')
plt.xlabel('Sex')
plt.ylabel('Species')
plt.show()
'프로그래밍 > Python' 카테고리의 다른 글
| [Python] Input/Output (0) | 2024.11.07 |
|---|---|
| [Python] 웹 스크래핑 라이브러리 - Selenium (0) | 2024.04.04 |
| [Python] 웹 스크래핑 라이브러리 - beautifulsoup (1) | 2024.04.03 |
| [Python] PEP8 스타일 (0) | 2024.03.28 |
| [Python] 큐(Queue) (0) | 2024.03.28 |