
Seung's Learning Record
[Data Engineering] 데이터 파이프라인(Data Pipeline) 개념 정리 본문
데이터 파이프라인(Data Pipeline) 이란?
데이터 파이프라인은 다양한 데이터 소스에서 수집된 원시 데이터가 분석을 위해 데이터 레이크 또는 데이터 웨어하우스와 같은 데이터 저장소로 이동하면서 여러 단계를 거쳐 처리되는 흐름을 말한다. 데이터 파이프라인의 목적은 데이터의 수집, 변환, 저장, 분석 및 시각화를 자동화하고 효율화하는 것이다. 이를 통해 데이터가 일관되게 처리되고, 유의미한 정보를 제공할 수 있게된다.
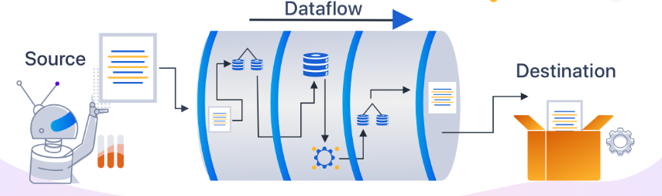
데이터 파이프라인 주요 아키텍처
- 데이터 수집 (Data Ingestion)
- 데이터 파이프라인의 첫 단계로, 여러 출처(데이터베이스, API, 로그 파일, 센서 등)에서 데이터를 수집한다.
- 데이터 수집 도구로는 Apache Kafka, Apache Flume, AWS Kinesis 등이 사용된다.
- 데이터 전처리 (Data Preprocessing)
- 수집된 데이터를 정리하고 변환하는 단계로 결측값 처리, 중복 제거, 데이터 정규화, 형식 변환 등의 작업이 이루어진다.
- 이 단계에서는 Apache Spark, Apache Beam, Pandas 등이 사용된다.
- 데이터 저장 (Data Storage):
- 전처리된 데이터를 데이터 웨어하우스, 데이터 레이크, NoSQL 데이터베이스 등 다양한 저장소에 저장하는 단계이다.
- 데이터 변환 (Data Transformation):
- 저장된 데이터를 분석 목적에 맞게 변환하는 단계이다.
- ETL(Extract, Transform, Load) 또는 ELT(Extract, Load, Transform) 과정으로 진행됩니다.
- SQL, Apache Spark, Apache Nifi 등의 도구가 사용된다.
- 데이터 분석 (Data Analysis):
- 변환된 데이터를 분석하고, 유의미한 정보를 단계이다.
- 도구로는 Python, R, Apache Spark MLlib 등이 사용된다.
- 데이터 모니터링 및 로깅 (Data Monitoring and Logging):
- 파이프라인의 오류를 감지하고, 성능을 추적하며, 문제 발생 시 신속하게 대응할 수 있도록, 데이터 파이프라인의 상태를 지속적으로 모니터링하고 로그를 기록하는 단계이다.
- 도구로는 Prometheus, Grafana, ELK Stack 등이 사용된다.
데이터 파이프라인 유형
데이터 파이프라인에는 여러 처리 유형이 있지만 그중 가장 대표적인 유형은 스트리밍 처리 유형과 배치 처리 유형 이다.
스트리밍 데이터 파이프라인 (Streaming Data Pipeline)
스트리밍 데이터 파이프라인은 실시간으로 데이터를 수집하고 처리하는 파이프라인으로, 데이터가 발생하는 즉시 시스템에 의해 처리되고 분석된다. 이 유형의 파이프라인은 연속적으로 작은 단위의 데이터가 들어오며, 낮은 지연 시간으로 실시간 분석과 반응을 가능하게 한다.
스트리밍 처리는 실시간 분석, 모니터링 및 경고 시스템, 실시간 추천 등과 같이 즉각적인 처리를 요구하는 상황에서 주로 사용된다.
배치 데이터 파이프라인 (Batch Data Pipeline)
배치 데이터 파이프라인은 일정 시간 간격으로 데이터를 수집하고 일괄 처리하는 파이프라인이다. 대규모 데이터를 모아서 한꺼번에 처리하는 방식으로, 주기적으로 데이터 처리를 수행한다. 일반적으로 대용량 데이터에 대한 작업으로 전체 시스템에 부담을 줄 수 있는 일괄 처리 작업이 다른 워크로드에 미치는 영향을 최소화하기 위해 사용량이 적은 업무 시간에 진행된다.
배치 처리는 데이터 웨어하우징, ETL Process, 리포팅 및 분석 등과 같은 대규모 데이터 분석 작업에 주로 사용된다.
비교
| 스트리밍 처리 | 배치 처리 | |
| 처리 방식 | 실시간 | 일괄 처리 |
| 지연 시간 | 낮음 | 높음 |
| 데이터 단위 | 작은 청크 | 대규모 데이터 |
| 처리 주기 | 지속적 | 주기적 (예: 매일, 매주) |
| 주요 사용 사례 | 실시간 분석, 모니터링, 실시간 추천 시스템 | 데이터 웨어하우징, ETL, 리포팅 |
| 주요 도구 | Apache Kafka, Apache Flink, Amazon Kinesis | Apache Hadoop, Apache Spark, Google BigQuery |
'DE' 카테고리의 다른 글
| [Data Engineering] ETL (Extract, Transform, Load)과 ELT (Extract, Load, Transform) 개념 정리 (0) | 2024.05.21 |
|---|
